今年初のオンライン勉強会は LT 枠で参加しました。
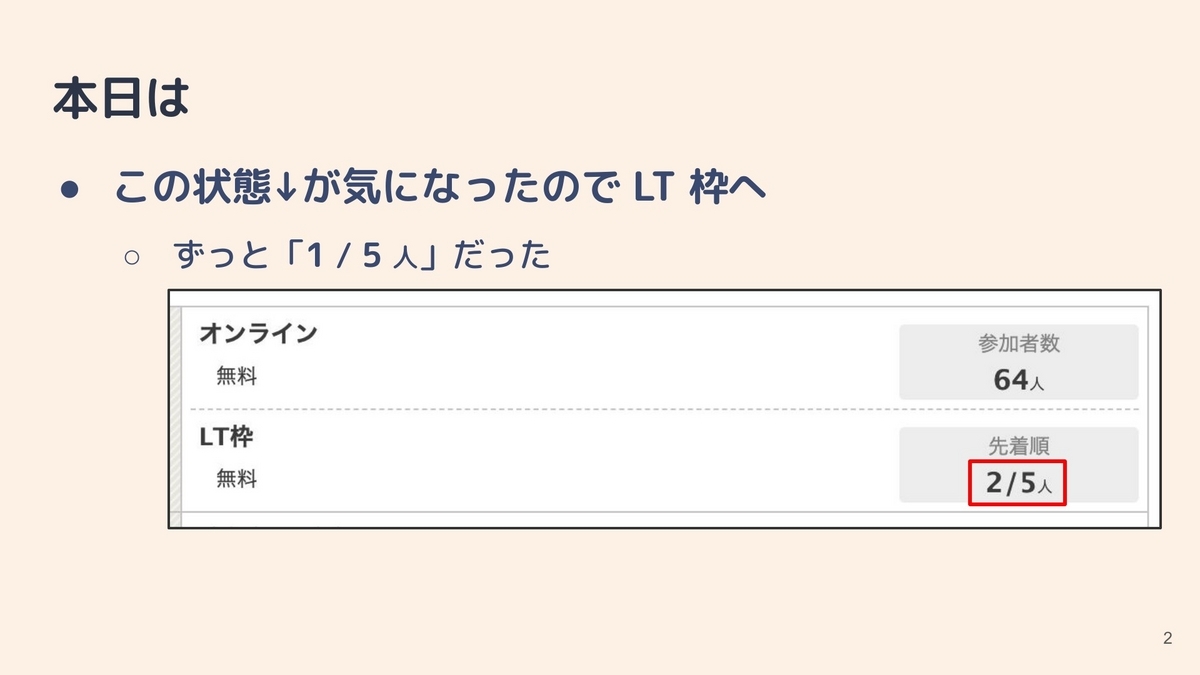
ということで。
あータグ間違えた!
— hmatsu47(まつ) (@hmatsu47) 2024年1月6日
いつもと違う景色を見ながら参加中。#jawsug #jawsugyokohama
togetter まとめはこちらです。
カスタムベクトルストアで RAG ワークフローをカスタマイズする(齋藤さん)
2023 AWS Jr. Champion(s) の齋藤さんが Vector Engine for Amazon OpenSearch Servelerless を使って Knowledge Base for Amazon Bedrock を試してみたお話でした。
Knowledge Base for Amazon Bedrock、今年のアドベントカレンダーでいろんな Vector Store を使って試している人がいましたね。
hirutaさんがさっきポストされてたAurora PostgreSQLをVectore Storeとして使う話は、去年のアドカレでセゾン情報システムズのhayao_kさんが記事を書かれてましたね。https://t.co/2txeCrTNng
— hmatsu47(まつ) (@hmatsu47) 2024年1月6日
#jawsugyokohama
我らが(?)pgvector(Aurora PostgreSQL)を使う例はセゾン情報システムズの hayao_k さんが試されていました。
LT の後、運営の吉田さんが齋藤さんを質問攻めにされていたのが印象的(?)でした。
(RAG をどうカスタマイズして「使い物になる」ようにするか?は奥が深いですからね。なので質問にも力が入ります)
RDS Data API のその後と Aurora zero-ETL 統合のデータ転送処理の話
わたしのパートでした。
RDS Data API は「Aurora Serverless v1 にしか対応していないのに、なんでこのタイミングで AppSync 連携強化を出してきたんだろう?」と思っていたら 12/21 になって「Aurora PostgreSQL Serverless v2 / Provisioned 対応」が出てきて「あー、そういうことか」と。
そして Aurora to Redshift の zero-ETL 統合では、意外と知られていないようですが普通の binary log / logical replication ではなく「enhanced」な binary log / logical replication によってストレージ層でデータ転送しているよ、という話をしました。
それにしても Aurora PostgreSQL の enhanced logical replication、扱いが地味すぎますね。
あと、(本編で触れる余裕はなかったのですが)LT 後の質疑で「DMS との使い分け」の文脈で出てきた「列フィルタできない」件。
「ETL じゃなくて ELT として使う思想なのでは?」という話もありますが、
- テーブル単位の除外ができない(もしくは非推奨)
- 列の除外もできない
となると、zero-ETL 統合対象の DB にBLOBなど Redshift に zero-ETL 統合で転送できない型の列を持つテーブルがあると、そもそも Redshift にロード(L)すらできない のが問題ですね。
特に PostgreSQL の logical replication はレプリケーション対象のテーブルの選択、列の選択などが柔軟にできるのが特徴の 1 つでもありますし、それを生かさないのは…。
(まあストリーミングレプリケーション的に zero-ETL 統合の本体で WAL を直接食う設計にすると PostgreSQL のバージョンごとに実装を変える必要が出てきそうなので、その部分を enhanced logical replication という形で分けてしまおう、という考えになるのはわかる気もするのですが)
ちなみに、MySQL HeatWave では列フィルタが可能です。
re:Invent 2023 でのデータベース関連アップデート項目をひととおり眺めるパート(大栗さんを中心に)
Aurora Limitless Database と Vector Store / Search 祭り・zero-ETL 統合祭り以外はそんなに目立つものがなかった印象です。
なお Aurora Limitless Database もそうですが、最近の Aurora は MySQL より PostgreSQL が先行して新機能を実装してきている点も気になりますね。
その他
運営の神田さんに(Zoom で)久しぶりのご挨拶ができました!
(コロナ前以来?)